During the first session of the BeSA program I got hands-on with Amazon Bedrock Agents and built a fully working AI shopping assistant from scratch. Here’s what shifted in my thinking.
February 2026 · 7 min read
Amazon Bedrock Agentic AI AWS Lambda RAG Multi-Agent BeSA
There’s a concept that sounds obvious once you hear it, but takes hands-on experience to really internalize: the difference between AI that answers and AI that acts.
That was the core of what we explored during the first session of BeSA Batch 09 — and it changed how I think about building with AI.
From GenAI to Agentic AI: a shift in paradigm
Standard Generative AI is a brain. Ask it to plan a trip and it’ll give you a beautiful itinerary — but it leaves the actual booking to you. Agentic AI adds hands to that brain. The main difference is the shift from “responding” to “doing.” GenAI plans and answers. Agentic AI plans and executes — using an LLM as a decision center, equipped with tools like APIs, databases, and Lambda functions that let it act autonomously.
“Agentic AI isn’t a trend — it’s a paradigm shift. From tools that help us write, to systems that do the work for us.”
Think of a football manager. His goal is to win the match (the user prompt). He reads the game, sets the tactics, decides which players to put on the pitch and when — and when the plan stops working, he adjusts at half-time. He doesn’t kick the ball himself, but every outcome depends on his decisions. A well-built AI agent works exactly the same way: it receives the goal, figures out which tools to deploy, orchestrates the execution, and replans when something unexpected happens.
The anatomy of an agent
An AI agent isn’t magic — it’s four things working together:
1. The Brain (LLM) — responsible for reasoning and decision-making. The choice of model matters enormously: in this workshop, Claude 3.5/4.5 Sonnet was recommended specifically because of how well it handles task orchestration.
2. Planning & Orchestration — the ability to break a complex goal into steps and correct course in real time. This is what separates an agent from a simple chatbot.
3. Tools (Action Groups) — the connection to the outside world. API calls, Lambda functions, database queries. This is where the agent stops talking and starts doing.
4. Memory — context from previous interactions so the agent doesn’t repeat itself, doesn’t ask for the same information twice, and can learn from what’s already happened in the session.
·
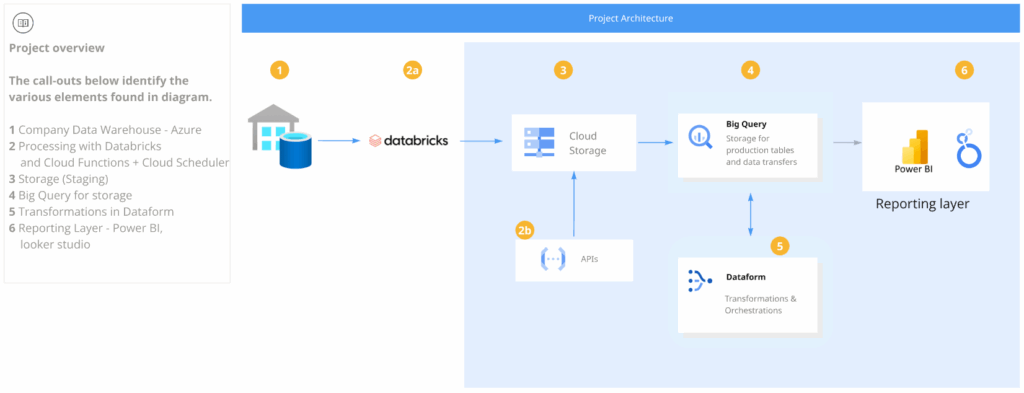
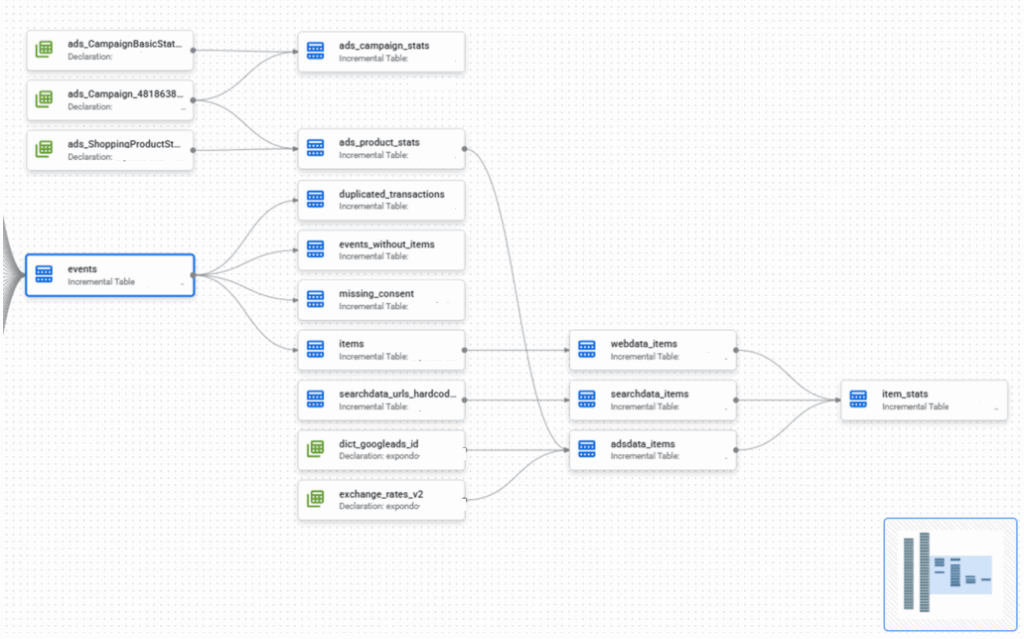
Building it in Amazon Bedrock
The workshop was a hands-on implementation of all of the above. The goal: build a conversational shopping assistant that could recommend gifts, manage a cart, personalize upsells, answer questions about gift wrapping, and — in the final section — delegate work to specialized sub-agents.
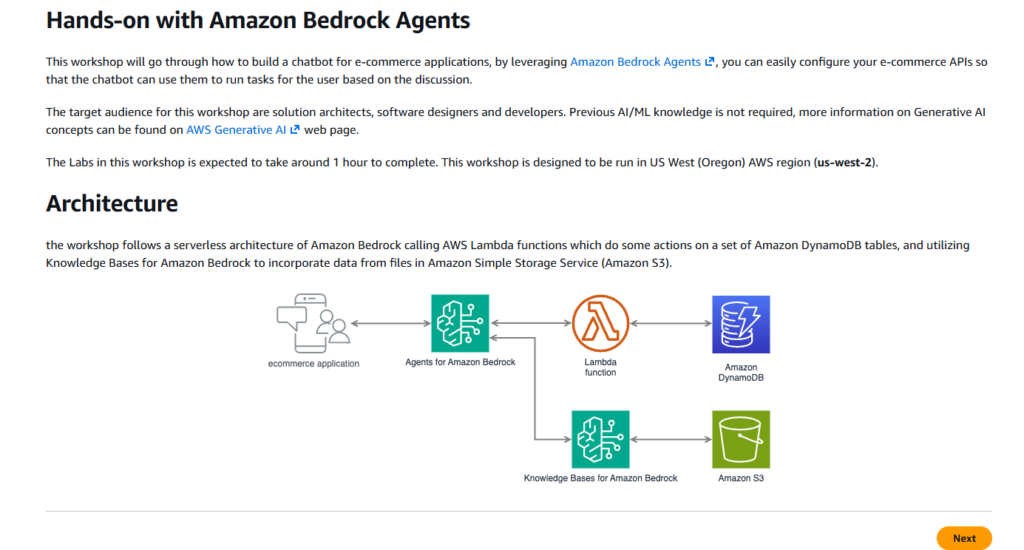
All of it on a serverless AWS stack.
The starting point was creating an agent in the Bedrock console, selecting Claude Sonnet 4.5 as the model, and writing the system prompt — the instructions that define the agent’s role and boundaries. One of the key lessons: don’t rush, and read carefully. A vague prompt produces a vague agent. Precise instructions about when to call a tool, how to handle missing parameters, and what never to reveal to the user — that’s what separates a good agent from a frustrating one.
Action Groups: connecting the agent to the real world
Each capability was added as an Action Group — a binding between the agent’s reasoning and a Lambda function. The agent learned to call a products API to filter by gender, occasion, and category. Then a cart API to add and retrieve items. Then a Personalize API to surface “customers who bought this also bought…” recommendations automatically after every cart addition.
The agent didn’t follow a fixed script for any of this. It reasoned about the conversation, decided which tool to invoke, constructed the right parameters, and presented the result naturally.
Knowledge Bases and RAG
Not all useful information fits in an API. For gift wrapping ideas, the workshop introduced a Knowledge Base backed by a plain text file in Amazon S3. Using Retrieval Augmented Generation, the agent could pull relevant passages from that document and weave them into responses — grounded in real content, without any model retraining. A fully managed RAG pipeline, ready in minutes.
Multi-Agent Collaboration
The most architecturally interesting section was the last one. Instead of one agent doing everything, I built three: a product specialist, a cart specialist, and a supervisor that coordinates them. The supervisor routes requests to the right sub-agent and shares conversation history between them — so the cart agent knows which product was selected three messages ago without the user having to repeat themselves.
Multi-agent isn’t just a scaling trick. Specialized agents are easier to test, update, and reason about in isolation. It’s a cleaner architecture for anything non-trivial — and it’s how you’d build this for production.
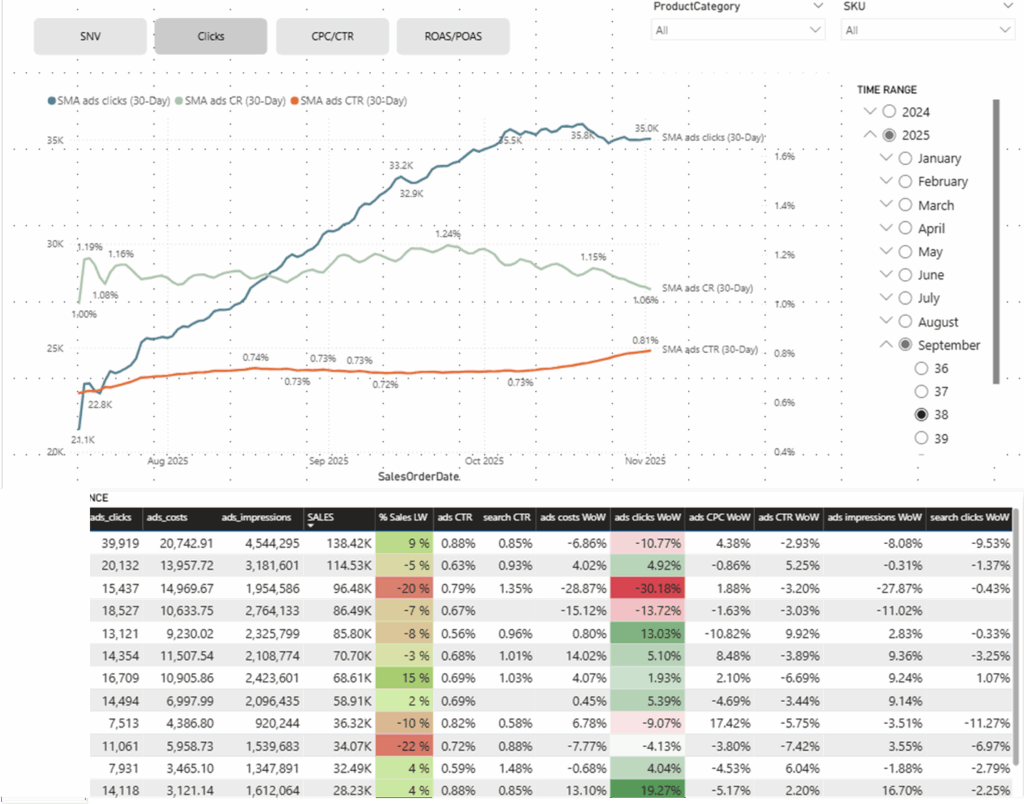
The agent in action
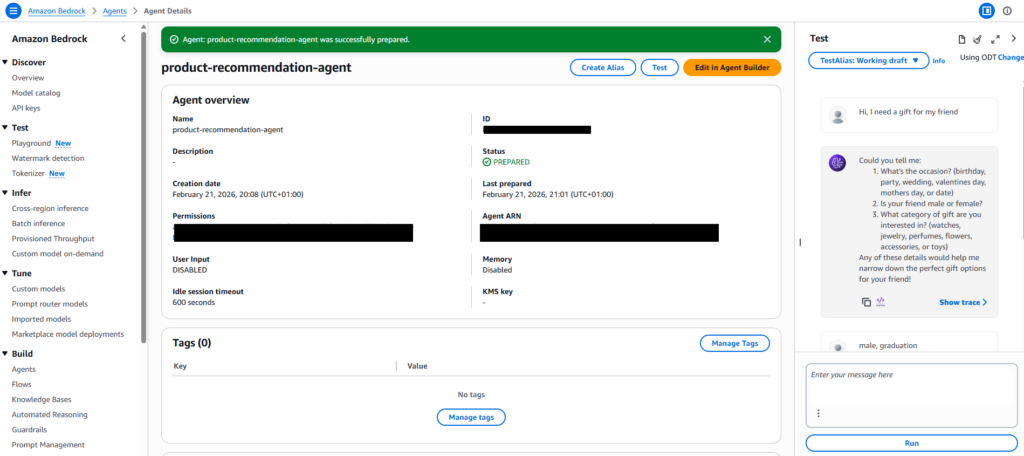
The screenshot above captures something that required a lot to make work: the agent asked the right questions to narrow down its API call, then returned a curated list — not a database dump. That’s the difference between a search interface and an assistant.
The trace inspector in Bedrock was the most valuable debugging tool. Expanding any response reveals the agent’s raw reasoning: which action group was invoked, what parameters were sent to Lambda, and how the result was interpreted. Real observability into the model’s decision-making. It also drives home why model selection matters — the same configuration with the wrong model can simply stop working.
“Traces let you see why the agent did what it did. That’s not just a debugging feature — it’s a design tool.”
What this means going forward
We’re in what feels like a golden era for solution architects. Agentic AI doesn’t replace the architect — it gives the architect a new class of building block. One that can reason, plan, call APIs, retrieve context, and collaborate with other agents. The patterns we reach for when designing autonomous workflows are changing fast.
The practical things I’ll carry forward: write precise agent instructions. Use traces to understand behavior, not just whether it works. Pick the right model for orchestration. And think in systems — a supervisor coordinating specialists will almost always beat one overloaded generalist agent.
Workshop: Build a product recommendation chatbot with Amazon Bedrock Agents — AWS Workshop Studio · BeSA Batch 09